Nog steeds actueel:
Key Organizational-Infrastructure Requirements for Preservation Programs
(uit: Preservation in the Age of Large-Scale Digitization. A White Paper, by Oya Y. Rieger.
Februari 2008.
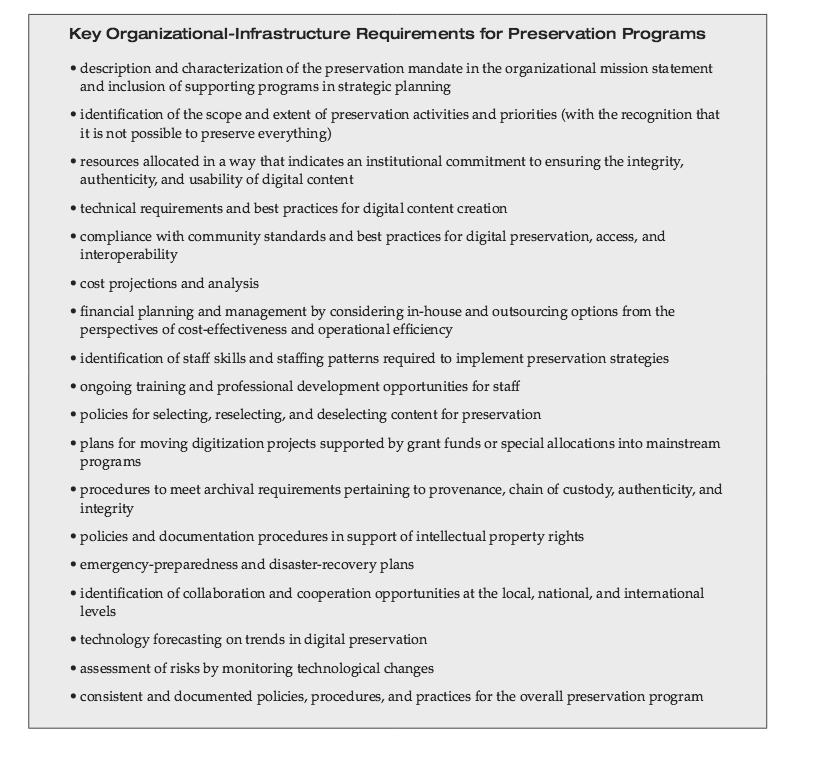

Nog steeds actueel:
Key Organizational-Infrastructure Requirements for Preservation Programs
(uit: Preservation in the Age of Large-Scale Digitization. A White Paper, by Oya Y. Rieger.
Februari 2008.
De voorspelling is dat in 2050 90 % van de bevolking wereldwijd in steden woont. Hoe houden we die steden leefbaar? Hoe zal die stad eruit zien? Ik heb hieronder twee video’s opgenomen over datgene wat ons te wachten staat, en hoe steden ‘slimmer’ worden.
De eerste video is een Australische aflevering van het programma Catalyst, waarin reporter Anja Taylor een aantal innovatieve ideeën onderzoekt om onze toekomstige steden te verbeteren. De film dateert uit 2014.
De tweede video is een samenstelling van drie afzonderlijke films over de het slimmer worden van brandstof, auto’s en gebouwen in 2050. Welke slimme technologie moeten we toepassen om de wereld leefbaar te houden? Welke rol speelt ‘smart technology’?
De tweede video was in 2018 niet meer beschikbaar.
Afgelopen weken las ik Ger Biesta’s boek Het prachtige risico van onderwijs en Alderik Vissers artikel Marktfilosofie en onderwijsutopie. Beide onderwijsfilosofen maken ‘gehakt’ van de huidige onderwijspolitiek. Marktdenken leidde tot schaalvergroting, autonomie, outputfinanciering, prestatiebeurzen en -rankings. Marktdenken, bestuurlijke vrijheid en publieke verantwoording onderwierpen het onderwijs aan de ‘tucht’ van de markt, ‘maakbaar’ en ‘meetbaar’….
Onderwijs werd geprotocolleerd, van procedures voorzien, uitgerust met kwaliteitseisen, meetfactoren en benchmarks. Het werd omgezet in kwantificeerbare grootheden om de impact van onderwijs te meten. Docenten controleren en zijn ‘begeleider van een leerproces’. Onderwijskundigen, pedagogen, didactici en andere specialisten schrijven voor hoe het onderwijs moet worden verzorgd en bedenken daarvoor (u raadt het al) protocollen, formulieren, richtlijnen, procedures, beoordelingsformulieren en checklists. Onderwijsinstellingen zijn bureaucratische fabrieken, met talloze regels en protocollen, die op het bord worden gelegd van de arbeiders die het proces uitvoeren. De docenten dus.
Die klagen over regels, die hun werktijd belagen met administratie, informatieverwerking en ‘archivering’ in organisatiebrede, onduidelijk ontworpen informatiesystemen. Niet om het onderwijsproces te ondersteunen, maar om interne efficiency en compliance te bereiken. Compliance is het voldoen aan opgelegde regels en dat kunnen aantonen. Dit alles waarborgt de ‘kwaliteit’ van het onderwijs. Systeemkwaliteit, wel te verstaan, want die wordt continue getoetst in accreditatie-, opleidings- en instellingstoetsen. Talloze statistieken worden gemaakt, vaak met data die op onbetrouwbare wijze verzameld en beheerd zijn. Archiveringssystemen waarmee datakwaliteit gewaarborgd wordt, bestaan niet in onderwijsorganisaties. Het systeem legt nadruk op efficiency van de eigen processen, kosten en regelnaleving. Er wordt nauwelijks gelet op de effectiviteit van het onderwijs.
In politieke kringen zal Mintzberg’s The structuring of organizations niet onbekend zijn. Mintzberg schetste een aantal organisatieconfiguraties, elk met een andere bestuurs- en leiderschapsstijl. Onderwijsorganisaties zijn professionele organisaties, met hoogopgeleide werknemers, die veel zelfstandigheid in hun werk nodig hebben. Onderwijsorganisaties worden echter bestuurd en getoetst als machinebureaucratieën, strak geprotocolleerd, zonder ruimte voor onafhankelijkheid en zelfstandigheid. ‘Politiek Den Haag’ wenst immers maakbaarheid en meetbaarheid. ‘A recipe for disaster’.
Biesta en Visser geven aan hoe het anders zou kunnen: inhoudelijker, persoonlijker en met meer nadruk op individuele leerprocessen van studenten zelf. De student en het individuele leerproces centraal. Kleinere, op effectief onderwijs gerichte onderwijsorganisaties.
Een compliance-fabriek draagt niet bij aan de kwaliteit en de effectiviteit van het onderwijs. Helaas.
Voor de eerste keer gepubliceerd in IP. Vakblad voor Informatieprofessionals, 2015, nr. 7, p. 29.
Google en Facebook zijn twee Internet-giganten, die ongelooflijke hoeveelheden data verwerken en miljoenen interacties per dag verwerken. Vandaag twee filmpjes over de datacenters die daarvoor nodig zijn. Ze zijn niet zo lang, maar geven wel een goed beeld van de opslag- en verwerkingskracht die nodig is om als search- en social media site succes te kunnen hebben. Beide bedrijven hebben datacenters verspreid over de gehele wereld. Samen met datacenters van andere giganten (denk Amazon, Microsoft, Twitter) vormen deze datacenters ‘the backbone of the Internet’.
Voor Google:
Voor Facebook:
In META. Tijdschrift voor Bibliotheek en Archief, 2015, nr. 4, blz. 32-35, verscheen mijn artikel ‘Over Cloud en Big Data. Uitdagingen en onontkoombaarheid’. Het is als PDF te downloaden.
Ik sluit dat artikel af met de volgende bespiegeling:
“Cloud computing wordt in tijden van bezuiniging vooral gezien als een mogelijke en interessante automatiseringsoptie, ook in bibliotheken, musea en archieven. Het concept biedt vele mogelijkheden om kosten te besparen en tegelijkertijd kwaliteit en performance te verhogen. Uiteraard kunnen die laatste twee alleen indien de hiervoor aangegeven uitdagingen en juridische complicaties kunnen worden ondervangen. Veel organisaties zijn echter vooral gecharmeerd door de kostenverminderingen die kunnen worden gerealiseerd en de mogelijkheden om de eigen, complexe informatie infrastructuren af te bouwen. Ze zijn zich niet echt bewust van de potentiële problematiek, die cloud computing en Big Data met zich meebrengen. Juist die uitdagingen en complicaties echter oefenen rechtstreeks invloed uit op de performance van bedrijfsprocessen en zijn niet zomaar te ondervangen. Dat vergt nogal wat, waardoor het van belang is de organisatorische risico’s goed in kaart te brengen en af te wegen.”
Citatie: G.J. van Bussel, ‘Over Cloud en Big Data, Uitdagingen en onontkoombaarheid’, META. Tijdschrift voor Biblotheek en Archief, 2015, nr. 4, pp. 32-35.
De Cost of Inaction Calculator is een model dat in 2014 gepresenteerd is door de University of Indiana. Het is een model dat gebruikt kan worden in de consterverings- en preservaringsactiviteiten van cultureel-historische instellingen.
Bekijk de website hier.
Bekijk een webcast over het waarom van dit model hieronder:
Een video van de presentatie van Jerome McDonough, een associate professor Library and Information Studies aan de University of Illinois. In december 2014 hield McDonough een presentatie bij een seminar van de Coalition for Networked Information over Digital Preservation en de rol van de huidige instellingen als beheerders van cultureel historisch erfgoed. De presentatie wordt als volgt aangekondigd:
“Existing digital preservation efforts typically occur within the institutional contexts of libraries, archives, and museums, and focus on materials held to serve a given institution’s designated community. While there has been significant work over the last two decades on methods, models and best practices for digital preservation, as a community, we have paid less attention to the issue of whether our institutions themselves are designed in a way which facilitates long-term access to cultural heritage materials. This talk will identify ways in which the larger institutional structures within which preservation activities occur impede the preservation of cultural materials”.
De presentatie begint intrigerend en erg yummi met een intro over de Japanse keuken….
Wat dat met het verhaal te maken heeft wordt duidelijk, maar er zijn een minuut of zeven nodig voordat het verhaal echt op gang komt.
A little bit of humour!
Een infographic waarin de ontwikkeling van educatieve technologie gedurende de geschiedenis uit de doeken wordt gedaan. Met grote sprongen gauw thuis, maar dat is uiteraard een karaktertrek van een infographic. Deze visualisatie is er vooral op gericht te laten zien hoe technologie (en vooral mobiele technologie) een rol speelt in de mogelijkheden van mensen om informatie te verwerken en te leren. Een interessante weergave, waar nog heel veel meer over te zeggen is!

James Glanz van The New York Times en Ken Brill, oprichter van het Uptime Institute en een specialist in Datacenters en Cloud Computing bezoeken een datacenter en laten zien wat er nodig is om die continue in bedrijf te houden. Een zeer instructieve video van de New York Times, die hier te zien is.
De video is zeer aan te bevelen. Het maakt duidelijk wat er allemaal nodig is voor het in stand houden van bijvoorbeeld het World Wide Web. Cloud is een mooi woord, maar uiteindelijk is er natuurlijk een robuuste fysieke infrastructuur nodig, die een enorme aanslag doet op de jaarlijkse energieproductie!
Voor een overzicht van de uitdagingen waarvoor Digital Archiving gesteld wordt, zie een overzicht van artikelen, boeken en video’s bij Group47.
In Electronic Journal of Information Systems Evaluation, Vol. 18 (2015), nr. 2, pp. 187-198 en 199-209 (let op: afwijkende paginanummering in bijgevoegde PDFs!) verschenen twee papers van mijn (gedeelde) hand. Deze papers zijn bewerkingen van twee conferentiepapers uit 2014, gepresenteerd bij de European Conference on Information Systems Management Evaluation (Gent). Deze beide conferentiepapers zijn ook op deze site gepubliceerd. In EJISE zijn aanzienlijk uitgebreide en gewijzigde versies van deze papers gepubliceerd. De papers zijn door de redacteuren geselecteerd uit alle bijdragen voor de ECIME conferentie en zijn in hun gewijzigde vorm opnieuw door een double-blind peer review gegaan, net als de conferentiepapers eerder. Voor de papers en hun citatie zie:
J. van de Pas, G.J. van Bussel, ‘Privacy lost – and found? The information value chain as a model to meet citizens’ concerns’, Electronic Journal of Information Systems Evaluation, vol. 18 (2015), nr. 2, pp. 199-209 (PDF).
G.J. van Bussel, N. Smit, J. van de Pas, ‘Digital Archiving, Green IT and Environment. Deleting data to manage critical effects of the Data Deluge’, Electronic Journal of Information Systems Evaluation, vol 18 (2015), nr. 2, pp. 187-198 (PDF)
Het volledige nummer van EJISE is hier te raadplegen.
Een video van de presentatie van Digital Media Strategist Sarah Werner tijdens de conferentie Digital Preservation 2013 over de ‘mutual concerns of digitizing and preserving cultural heritage’. Een interessant verhaal met heldere en veelzeggende voorbeelden. Een transcriptie van haar verhaal is te lezen (in een onopgemaakt tekstbestand) via de site van de Library of Congress, hier.
In januari voerde de Technische Universiteit Twente een onderzoek uit naar de wijze waarop de Amsterdamse burgers het liefst zouden communiceren met hun gemeente. Uit dat onderzoek bleek dat (ook de Internet-vaardige) burgers gebruik wensen te maken van kanalen waar persoonlijk contact domineert. De balie wordt het meest genoemd als communicatiekanaal (36%), gevolgd door de website (28%) en de telefoon (26%). Mobiele communicatiekanalen worden vrijwel niet gebruikt. De onderzoekers constateren dat er geen enkele aanleiding is om aan te nemen dat burgers de komende jaren massaal op het digitale communicatiekanaal zullen overstappen.
De overheid wil graag digitale dienstverlening: het verbetert de relatie met de burgers en de efficiëntie voor beide partijen verbetert aanzienlijk. Tenminste: dat denkt ‘men’. Digitale Overheid 2017 is gebaseerd op deze verwachting. Het Amsterdamse onderzoek is dan ook geen goed nieuws voor de ambitieuze bedenksels van de instigator van dit mega-project, onze minister van Binnenlandse Zaken Ronald Plasterk.
Burgers willen graag maatwerk en kleinschaligheid. Dit moet samen gaan met werken in grotere samenwerkingsverbanden, waar overheden steeds meer in participeren. Dit verwacht andere wijzen van werken, ver doorgevoerde digitalisering binnen de organisaties zelf en optimale toegankelijkheid van informatie. 80% van de gemeenten heeft de digitale informatiehuishouding niet op orde. Dossiers zijn niet vindbaar, beschikbaar en toegankelijk. En dat terwijl gemeenten zichzelf beschouwen als informatiegedreven organisaties!
De digitaliseringsmachine hapert al jaren. Parlementaire rapporten over falende ICT en mislukte ICT projecten (zoals dat van Elias) maken duidelijk dat de overheid haar regierol op ICT niet waarmaakt. Lokale overheden krijgen nieuwe taken, maar ook een Haagse ICT-erfenis. De kans is groot dat gemeenten hun ICT nog minder dan nu kunnen overzien, aansturen en betalen, met als gevolg bezuinigingen, belastingverhogingen en (nog) meer fouten. Informatie wordt nog onbetrouwbaarder, waardoor het afleggen van verantwoording zo goed als onmogelijk wordt. En dat terwijl (volgens de Nationale Ombudsman in 2013) slechts elf procent van de bevolking vertrouwen heeft in de manier waarop de overheid nu met informatie omgaat!
De Nationale Ombudsman heeft ook gewaarschuwd dat de digitale vaardigheden van vele burgers onvoldoende zijn om een primair digitaal communicatiekanaal te hanteren. Volgens de OECD Skills Outlook 2013 beschikt een aanzienlijke minderheid van de Nederlandse burgers over onvoldoende digitale geletterdheid om de weg te vinden in de vaak moeilijk toegankelijke overheidssites, die vaak weinig begrijpelijk en onvoldoende contextueel van opzet zijn. Tussen twaalf en vijftien procent van de Nederlandse bevolking heeft een lager lees- en schrijfvermogen dan de basisscholen als eindniveau zien. ‘Jip-en-Janneke-taal’ klinkt als term denigrerend, maar is voor een groep Nederlandse burgers een noodzaak om enig begrip te verwerven van wat de overheid wil.
Informatiegedreven overheid?
Misschien is een burgergedreven overheid beter, waarbij communicatie belangrijk is en niet het kanaal…
Voor de eerste keer gepubliceerd in IP. Vakblad voor Informatieprofessionals, 2015, nr. 6, p. 27
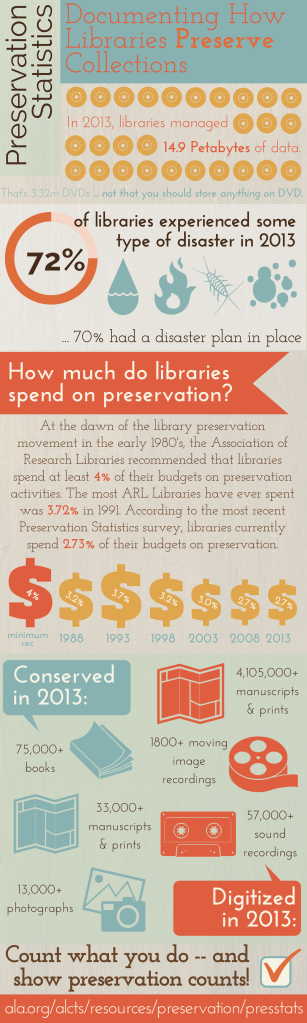
Het doel van de Preservation Statistics Survey is om de status quo van de preserveringsactiviteiten binnen bibliotheken via kwantitatieve data vast te leggen, zodat er vergelijking mogelijk wordt en veranderingen kunnen worden getraceerd binnen het preserverings- en conserveringsdomein. Hieronder staat een infographic van de resultaten van dit onderzoek over 2013. Opvallend is dat het bedrag dat in bibliotheken besteed wordt aan duurzaamheidsactiviteiten daalt. In 2013 was dit 2,73% van het totale budget tegen 3,2% in 1988. Voor de rapporten van deze survey over 2013 en 2014 (waarvan (zover ik weet) geen infographic beschikbaar is!) klik hier.
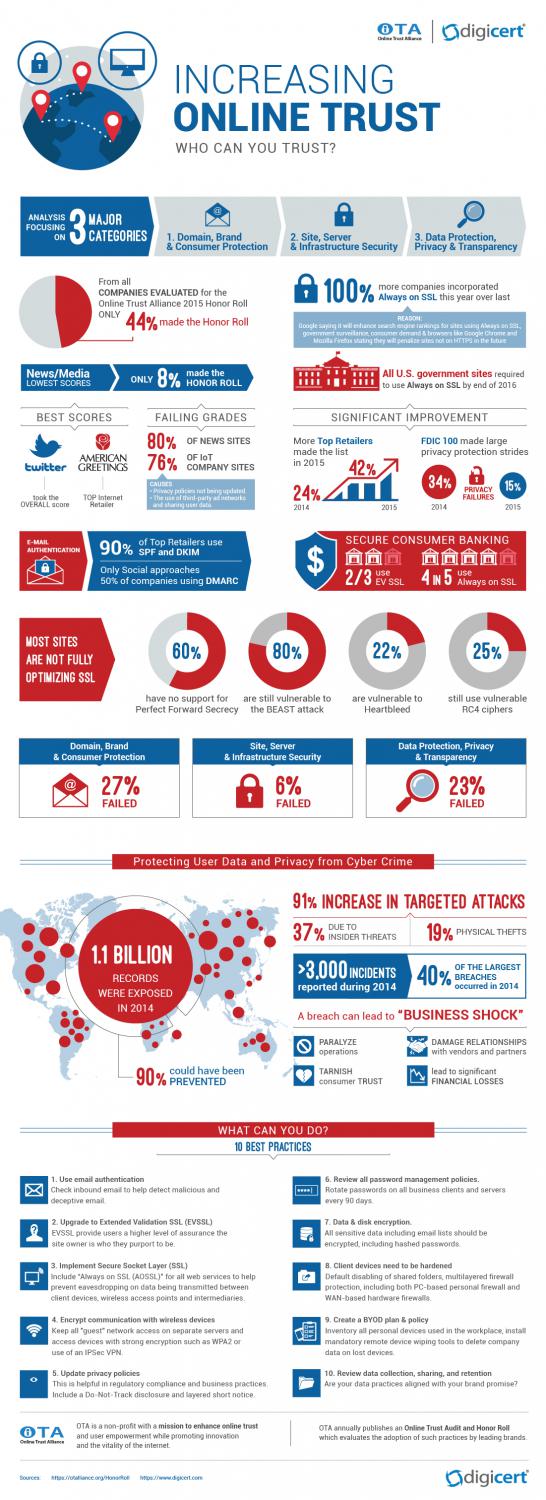
De Online Trust Alliance voert jaarlijks een audit uit naar de bescherming van burgers en hun gegevens. Voor 2015 werden bijna 1000 websites van grote banken, retailers, sociale media bedrijven, kranten, tv-bedrijven, uitgevers, muziekmaatschappijen, nieuwssites, regeringsinstellingen en Internet of Things-sites ge-audit. 44% van deze websites voldeed aan de criteria van klantbescherming en privacy. 45% van de bedrijven faalde hierin echter, wat zorgwekkend is. En let wel: dat de websites voldoen aan de criteria van klantbescherming en privacy betekent niet dat de privacy van klanten daadwerkelijk gewaarborgd is!
Watson is een computer systeem, dat als kunstmatige intelligentie zeer efficient is in het beantwoorden van vragen in natuurlijke taal. De computer is gebouwd door IBM door een onderzoeksgroep onder leiding van David Ferrucci. Watson werd genoemd naar de eerste CEO van IBM, Thomas J. Watson. Watson werd ‘beroemd’ door het winnen van Jeopardy! tegen vroegere winnaars Brad Rutters en Ken Jennings. Watson heeft toegang tot 200 miljoen webpagina’s met gestructureerde en ongestructureerde informatie, die ongeveer vier terabytes aan opslag in beslag nemen. De totale Wikipedia was in die opslag inbegrepen. Tijdens de show was de computer niet verbonden met het Internet. In februari 2013 werd door IBM de eerste commerciële toepassing van het Watson softwaresysteem aangekondigd. Watson wordt ingezet als hulp bij het nemen van beslissingen voor longkankerbehandelingen in de Memorial Sloan-Kettering Cancer Facility. Volgens IBM volgt 90% van de verpleegkundigen die Watson gebruiken de adviezen van de computer op. Deze film gaat in op Watson, zijn ontwikkeling en de de ontwikkeling ervan tot de slimste machine ter wereld.
Eric Schmidt stelde in 2010 dat op dat moment iedere twee dagen evenveel informatie gegenereerd werd als in alle jaren tot 2003 toe. Dat zou kunnen, al kan niemand het precies berekenen. Het is echter zeker dat de grote hoeveelheden informatie maatschappelijk succes en falen grotendeels afhankelijk maken van de informatievaardigheden die iemand heeft.
‘Information literacy’, de academische term om informatievaardigheden aan te duiden, is al meer dan drie decennia een populair onderzoeksthema. Google’s zoekmachine geeft 537.000 hits over het afgelopen jaar en 2.610.000 resultaten zonder tijdslimiet. Tientallen boeken en artikelen zijn er over geschreven, al gaan die meer over ‘technological literacy’ en over de ‘digitale vaardigheden’ van ‘digital natives’, ‘net savvy’s’ of ‘homo-zappiens’.
Vooral jonge mensen horen blijkbaar daartoe: ze zijn immers opgegroeid in een ICT-wereld, zijn vertrouwd met het gebruik van computers, mobiele apparaten, sociale media en het internet. Zij zijn de voorlopers van de nieuwe, digitale wereld, voor de voeten gelopen door de oudere generaties, die hooguit digitale immigranten kunnen zijn, niet in het bezit van de inherente technologische capaciteiten van jongere generaties. Het is ondertussen duidelijk geworden dat die beschrijvingen overdreven zijn.
Mijn ervaringen met studenten leren dat hun daadwerkelijke gebruik van ICT en de effectiviteit daarvan beperkter is dan gesuggereerd: gaming, SMS-en, snel zoeken op Internet, muziek en films downloaden of streamen en het gebruiken van sociale media. Vraag ze vooral niet om een spreadsheet te ontwerpen, een database in te richten of een data-analyse uit te voeren.
En overweg kunnen met technologie wil nog niet zeggen dat jongeren goed overweg kunnen met informatie. Livingstone heeft al in 2009 aangetoond dat het bij jongeren gaat om passieve consumptie van informatie. ‘Information literacy’ is echter allesbehalve passief. De Association of College and Research Libraries zegt dat een ‘information literate’ persoon kan bepalen welke informatie benodigd is, effectief en efficiënt benodigde informatie kan vinden en gebruiken, informatie en informatiebronnen kritisch kan beoordelen, geselecteerde informatie kan omzetten naar kennis, de economische, juridische en sociale effecten van informatie begrijpt en er ethisch en rechtmatig mee omgaat.
Grote groepen jongeren (en laten we eerlijk zijn: ook ouderen!) kunnen dat niet. Het wordt ze ook niet aangeleerd. In het hoger onderwijs verwacht iedereen dat jongeren die vaardigheden al hebben. Een module ‘informatievaardigheden’ in de propedeuse kan dan nog net, maar verder doen onderwijsinstellingen er niets mee.
Als er iets aan jongeren moet worden duidelijk gemaakt, dan is het wel dat kunnen omgaan met betrouwbare informatie cruciaal en onontkoombaar is. Informatievaardigheden behoren gedurende een totale schoolloopbaan te worden getraind, van basis- tot hoger onderwijs. Als dat bewustzijn er niet is dan zouden deze ‘digital natives’ wel eens een ‘lost generation’ kunnen worden.
Digitaal tenminste.
Voor de eerste keer gepubliceerd in IP. Vakblad voor Informatieprofessionals, 2015, nr. 5, p. 27.
In deze film gaat Geert-Jan van Bussel in op wat Digital Archiving is, wat de informatiewaardeketen daarvoor betekent en welke rol de dimensies van informatie daarin spelen. De film is bedoelt als een introductie in het thema en gericht op de bewustwording van het belang van Digital Archiving in onze informatiemaatschappij, met de opkomst van Big Data en de voortdurende groei in de hoeveelheid informatie, die toegankelijkheid en terugvindbaarheid van informatie bemoeilijkt. De film eindigt met een aantal praktische tips over hoe de problematiek kan worden benadert. De film duurt ongeveer een kwartier.
In 2008 schreef Chris Anderson, een redacteur bij Wired, dat de zondvloed aan data (later Big Data genoemd) en nieuwe analysetools de wetenschappelijke methode onnodig maakten en een nieuwe manier waren om de wereld te begrijpen. ‘Correlation supersedes causation, and science can advance even without coherent models, unified theories, or really any mechanistic explanation at all’.
Big Data blabla-ers (ook evangelisten genoemd) hebben deze idee met vele anekdotes ondersteund en verkondigd. Volgens hen breekt er een nieuwe tijd aan: de dataficatie van onze maatschappij maakt alles meetbaar en doet alle bestaande problemen verdwijnen. Gemakshalve wordt er aan voorbij gegaan dat (zoals onderzoeksbedrijf Gartner stelt) 55% van alle Big Data projecten mislukt, vooral omdat ze niet de optimistische resultaten leveren die vooraf zijn ingecalculeerd. Zélfs het paradepaardje van de Big Data evangelisten niet: het in 2008 gestarte Google Flu Trends (GFT). Het geprofeteerde succes bleek rafelrandjes te kennen. In 2014 werd in Science aangetoond dat de resultaten (nog steeds) niet overeenkwamen met de ‘echte’ feiten. Het voorspellen van grieptrends lukte vele malen beter met drie weken oude, op traditionele wijze verzamelde en geanalyseerde gegevens van griepcentra.
Het hebben dus van Big Data (vijfhonderd miljoen zoekvragen per dag!) wil niet zeggen dat visualisaties daaruit een accuraat beeld presenteren van wat er werkelijk gaande is. Dat kan niet als (zoals bij GFT) de gebruikte gegevens onbetrouwbaar en onjuist zijn en/of de verkeerde gegevens zijn verzameld of geselecteerd. In Science werd aangetoond dat betrouwbare voorspellingen voor de verspreiding van griep mogelijk zijn als de analyses uit Big Data gecombineerd worden met traditionele, wetenschappelijke vormen van gegevensverzameling en -analyse. Een van de problemen van GFT (en andere analyses uit Big Data) is dat de resultaten veelal niet gerepliceerd kunnen worden. Dit komt vooral doordat algoritmen, formules, zoektermen en dataselecties geheim zijn en eigendom van private bedrijven.
Ik waag te betwijfelen of we wel alleen op data kunnen vertrouwen als indicator voor beslissingen, welvaart of zingeving. Jay Liebowitz propageert in zijn boek Bursting the Big Data Bubble om naast de resultaten van data analyse in beslissingsprocessen (met dan ook nog een voorkeur voor ‘small data’) ruimte te laten voor ervaring en intuïtie.
Het is zeker dat door ervaring en intuïtie fouten gemaakt (en voorkomen!) worden. Het is zeker dat data beslissingen kunnen verbeteren (als ze objectief worden gebruikt!). Het is ook aangetoond dat we gegevens negeren als ze niet overeenkomen met wat we subjectief denken (zelfs als de objectiviteit van die gegevens vast staat!).
Big Data evangelisten verkondigen dat ‘you can only manage what you measure’. Blabla. Want de financiële crisis heeft aangetoond dat we slecht zijn in het managen van wat we meten. Mislukte fusies en productlanceringen, veelvuldige imagoproblemen en social media escapades geven aan dat we vooral beter moeten worden in het managen van datgene wat we niet kunnen meten.
Met of zonder Big Data.
Voor de eerste keer gepubliceerd in IP. Vakblad voor Informatieprofessionals, 2015, nr. 4, p. 25.
Herdrukt in: W. Bronsgeest, M. Wesseling, E. de Vries, R. Maes, Informatieprofessional 3.0. Strategische vaardigheden die u connected houden (Amsterdam: Adfo Books, 2017), pp. 217-218.
Deze week werd ik weer geconfronteerd met de uitspraak dat opslag van data goedkoop is en dat alles makkelijk kan worden bewaard voor een Big Data strategie. Ik kon mijn lachen niet inhouden. In 2000 kostte een gigabyte opslag gemiddeld €8,31, in 2010 €0,07. De toegenomen hoeveelheid data en het effectievere gebruik van opslaghardware in diezelfde periode zorgde voor die substantiële verlaging van de opslagprijzen. De springvloed in Thailand verhinderde een verdere verlaging van de opslagprijzen na 2011. Veertig procent van productiecapaciteit van opslagschijven werd toen vernietigd, waardoor de prijzen voor opslagschijven verdubbelden. Die prijzen zijn in het vervolg weer lager geworden, maar ze hebben het niveau van 2011 niet meer bereikt. Wat in in de gigabyte-opslagprijzen nooit is meegenomen is het gebruik en de terugvindbaarheid van data. Van 2002 tot 2010 zijn de softwarekosten daarvoor gestegen van €4,8 miljard tot €10,9 miljard. De reden voor die kostenstijging is het feit dat data betrouwbaar en duurzaam moeten zijn. Ze worden immers opgeslagen om te worden gebruikt.
Na 2011 stijgt de hoeveelheid data en databestanden explosief (naar ‘multiple zettabytes’ in 2020, volgens onderzoeksbureau IDC). Hoewel een groot deel van die stijging te wijten valt aan ‘streaming’ video en audio, vergen de hoeveelheden daadwerkelijk opgeslagen data (ongeveer 20% van die ‘multiple zettabytes’) steeds meer capaciteit.
Het information governance regime nodig voor vertrouwelijkheid, privacy, compliance en erfgoed vergt met de stijging van de hoeveelheid data meer investeringen in software.
Maar hoe hoog zijn die kosten dan? Twee voorbeelden.
Het Internet Archive heeft de goedkoopste oplossing in gebruik, volledig geautomatiseerd, met weinig management en simpele procedures. In 2011 had het twee petabytes aan webarchief en groeide het met een kwart petabyte per jaar. De jaarlijkse kosten bedroegen tussen €9 en €13 miljoen per jaar, gemiddeld €0,40 per gigabyte. Portico verzamelt academische literatuur in een edepot, met nadruk op management en kwaliteitsprocedures. In 2011 had het vijftig terabytes in beheer en groeide het met vijf terabytes per jaar. De kosten bedroegen €5 tot €6,5 miljoen per jaar, gemiddeld €9 per gigabyte. Na 2011 hebben ze (gezien de groei in de hoeveelheid te bewaren data) hun opslagcapaciteit uitgebreid. De gemiddelde opslagkosten per gigabyte zijn ongeveer hetzelfde gebleven, maar er is een stijgende lijn te constateren.
Stel dat we een exabyte wereldwijd bewaren (een miljard gigabytes). Dat is een half promille van de wereldwijd geproduceerde twee zettabytes (twee duizend exabytes) aan data in 2011. We slaan ongeveer 20 % (vierhonderd exabytes) daarvan op. Het bewaren van die ene exabyte kost volgens het Internet Archive €400 miljoen en volgens Portico €9 miljard per jaar.
In 2020 produceren we misschien vijftien of twintig zettabytes!
Het verdwijnen van data, waar Vint Cerf onlangs voor waarschuwde, is zo erg nog niet.
Waarderen, selecteren en vernietigen van data wordt enorm belangrijk. Bibliothecarissen en archivarissen zullen er hun handen vol aan hebben.
Alles bewaren is totale waanzin.
Voor de eerste keer gepubliceerd in IP. Vakblad voor Informatieprofessionals, 2015, nr. 3, p. 29.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}